Here I would like to describe a model on how we organize storage of release metadata for technology products. This methodology is a part of new Reliza’s project ReARM. This may refer to both software or hardware or a mix of the two.
Table of Contents
I Problem Statement
Various regulatory requirements are either mandating already or are going to mandate in the future that vendors provide detailed metadata about their technology products.
For example, refer to https://www.nist.gov/itl/executive-order-14028-improving-nations-cybersecurity and https://digital-strategy.ec.europa.eu/en/policies/cyber-resilience-act .
Regardless of regulators, many organizations are already implementing requirements for vendors to provide detailed information about their products – this may include BOMs (Bills of Materials), VDRs (Vulnerability Disclosure Reports), VEXs (Vulnerability Exploitability eXchanges), SARIF files (Static Analysis Results Interchange Format), Attestations and other related artifacts. Explanations of what some of those are about may be found on the CycloneDX website.
Let us now place those requirements on top of the problem of combinatorial explosion of versions – and we can see that it is fairly difficult to organize all the required metadata in a sensible and accessible way.
II Problem Use-Cases
Here are some examples that came up during various stage of our research at Reliza and in TEA conversations:
- Software Product consisting of several microservices, deployable on Kubernetes and Docker Compose. The composition on Kubernetes and Docker Compose has minor differences, such that Kubernetes has extra microservices and a Helm chart. Essentially, we are dealing with 2 possible packages that may be provided to the end-user – Docker Compose or Kubernetes with a lot but not all components being shared between the two.
- Medical equipment that comes in different language versions – English and French. Each language version has its own model version. It may happen that a fixed spelling mistake in French increments French device model version, while English model is not affected – while the hardware remains exactly the same.
- An aerial drone that comes in different packages – one has extra battery, another has different remote and an extra set of propeller blades.
Note that in all above cases on top of different packages we are aiming to represent software or hardware development process as well – such as different branches, security patches, feature variations.
III Release Metadata Flow Chart
Below is the Flow Chart representation of the proposed solution. I will further describe it in subsequent sections (click to expand):
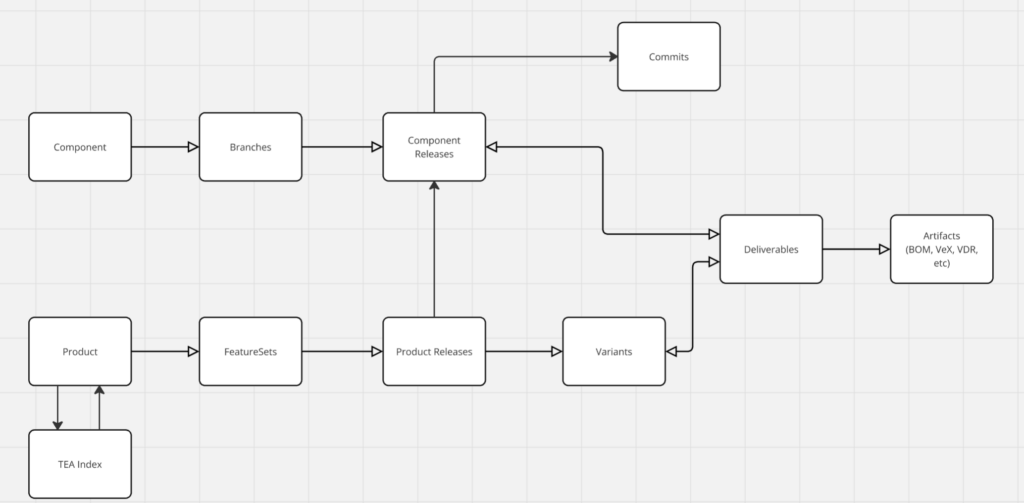
IV Component Level
Component is an atomic building block of an information technology system. For example, this could be a Java library or a single microservice, or a hardware component – such as drone battery.
Note, that atomicity here is subjective – since usually components may be divided into sub-components, but such division is impractical to track for a vendor. Such sub-components should still be listed in BOMs but they should not be the focus of our solution system.
Components have Branches that usually represent different feature or security postures. In the simplest case, only the Main Branch may be used.
Branches have Releases that are identified by versions. Each release has a collection of Deliverables. For a software product, Deliverables for the same release may consist of a jar file, a container image and a Debian package. For a hardware product, Deliverables may be used to represent specific inventory units, such as packaged battery and OEM battery.
Each Deliverable may have metadata Artifacts, which can be BOMs and Attachments (i.e. VEXs, VDRs, Attestations).
V Product Level
Now comes the Product level. While the Component level is mostly internal and vendor-facing, the Product level is customer facing. Product is a marketable representation of an information technology product.
From the product level we are planning to make connection to the Transparency Exchange API project mentioned above once it becomes available.
Meanwhile, Products have Feature Sets that are similar to Component’s Branches. Further, Product releases may have variants, in example a car may have S and LE variants for the same release model.
Essentially, the customer is dealing with a certain version of the Product and researches metadata and available artifacts specific for that version.
It is important to note that Products are composed of Components. In the most simple case, we may treat Product as a single Component, however that is usually not the case. To put less strain on the user of the system, we suggest using auto-integration functionality to automatically combine Components into Product releases.
VI Publisher Workflow
The publisher (Software or Hardware Vendor) must create entries for Components and Products they actively develop. Once that is done our system should allow for a set of automated options that populate our metadata storage on every new software or hardware release. Continuous Integration (CI) systems should be an optimal place to deploy such functionality.
Once everything is set up, the system should be populated automatically with no intervention on the publisher side.
VII Buyer / Compliance Workflow
Buyers or Regulators should be given restricted access into the system so that they can locate required artifacts based on the version or model numbers that they use.
Buyer access should be available on-demand, it is also suggested to allow functionality for notifications to registered buyers in case there is an update.
VIII Further Work
Currently, there is a lot of work done in Cybersecurity industry to establish functionality described above. We have released our OSS and commercial offering of ReARM earlier this year.
The base of the model has also been adopted in OWASP Transparency Exchange API (TEA).
If you are interested in this work, please connect with me via one of the platforms listed on the top right of my blog at worklifenotes.com. Note that this section has been updated in October 2025 with details about ReARM and TEA.
1 comment